I recently was tasked with performing an ETL task that should be done as efficiently and quickly as possible. The work led me to learn more about parallel and distributed processing in Clojure. In addition to having a greater appreciation for what Clojure enables (once again), I also pushed the boundaries of what I thought is possible using the available tools. I ultimately ended up writing a Spark job whose executors are each running N threads (currently, N=3). But the path to that solution taught as much by what didn’t work as much as what did work.
core.async vs. Distributed Execution
What people refer to as “lightweight threads” also gets referred to in the Clojure world as “go routines” (or much less frequently “Communicating Sequential Processes” / CSP). And the Clojure world has the benefit of core.async, a library, to be able to implement asynchronous processing via go routines and their channels on the JVM in a simple way.
I was initially thinking of writing a single process application that would use core.async to spin up hundreds of go routines in order to achieve the parallelism needed to finish the job quickly. I found that Clojure for the Brave and True‘s chapter on core.async was by far and away the best introduction to the topic. I was able to use that knowledge to create utility functions for myself that allowed me to build async pipelines of go routines much like one would create a topology of spouts and bolts in Storm.
But the one problem that I overlooked in the async exploration is that the bulk of the work in my ETL task is that a majority of the time spent doing blocking I/O operations. I have to download several files before I can parse them, filter them, and store the results elsewhere. Both the core.async documentation and the chapter from Clojure for the Brave and True explicitly mentioned that you should demarcate regions of blocking I/O in your async pipelines, so that a full thread can be dedicated to the I/O. They also said that async shouldn’t really be used if heavy I/O is the majority of what you do. The reason seems obvious in hindsight — you only have so many threads available to use before you saturate either your CPU or bandwidth resources. Oops.
Having the chance to learn about core.async and try it out was cool. I have a greater appreciation for how it motivated the creation of a library for Clojure that implements the idea of transducers. I had the chance to create utility functions that create a Storm-esque linear pipeline of async go-routines. But what I needed is lots of threads to handle the downloading of lots of files, and if one process has a limit to the number of threads it supports, then I needed many processes. In other words, I needed a distributed job.
Storm vs. MapReduce vs. Spark
My first thought was about writing a Storm topology to perform the task. Storm is fast because computation happens in memory and the data flows over the network. Disk storage is not a real part of the process. Storm is most effectively used for processing data completely independently, as it is for this ETL task, where it is effectively maps and filters and some shuffling. The downside is that Storm is also designed for handling real-time data, so it doesn’t have a true “off switch”, whereas my ETL job is a batch operation. Using Storm in the mode that simulates batch operations leaves the Storm cluster idle in between batch operation instances.
Because the ETL task is fundamentally a batch operation in nature, a batch system is more appropriate. I first thought of MapReduce (of course via a DSL like Cascalog or Scalding), but the problem here is that I cannot control the parallelism value during the map phase of a MR job. In Storm and in Spark, you can control the parallelism value (Storm – number of worker processes and bolt executor threads; Spark – number of executor processes). That ruled out MapReduce because it doesn’t let me fully guarantee that I can fully optimize the performance of the overall task on demand, as needed. It’s technically the decision of the MR job running on the YARN cluster as to how much resources my job would get.
The last option is Spark, which satisfies the requirements. It’s a distributed processing system, meaning many processes running the same job in a coordinated fashion. It runs in a batch mode. And I can control the parallelism. Although I didn’t and still don’t understand the full internals of how Spark manages memory for operations like .groupBy and how it handles data serialization in memory, for basic independent operations, it gave no real problems.
I used Flambo, a Clojure wrapper library for Spark, to implement my Spark job. The instructions for Flambo are pretty straightforward. It took a half a day to convert my async job into a Flambo Spark job. It took 1 day’s worth of time to figure out the serialization problems I was having with Flambo because I was new to it and didn’t fully understand how closures (Clojure fn objects) were being serialized. All in all, I think Flambo is pretty good and remarkably simple. I didn’t get a chance to use Sparkling long enough to be successful with it, so I can’t say much about it.
I didn’t have enough time to learn about and test out Onyx, which I regret. I have confidence that Onyx is able to deliver on its promises of simplifying the effort of distributed computing, unifying stream- and batch-processing, performing/exceeding Storm’s processing rates, and being production-grade reliable. core.async factors in a lot of Onyx examples, to the point where knowing core.async is almost like a prerequisite.
Multi-threaded Spark Jobs
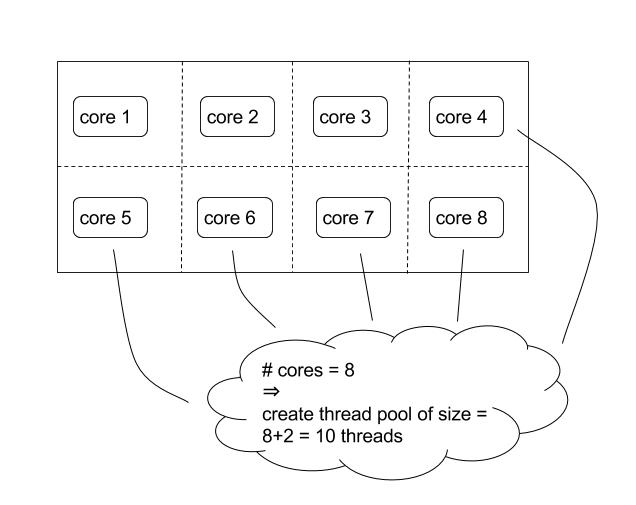
So the cool part begins when, after getting the Spark job up and running, a colleague half-jokingly suggests that if I was so excited about async threads and now converted to Spark, why don’t I put those 2 together and have async threads in the Spark job? And I actually did try exactly that same thing. The job crawled to a halt before ending with an runtime error that I didn’t trust at face value to indicate the exact source of the problem (maybe it was yet another OutOfMemoryError?). I speculated that the reason is that core.async go routines, just like Clojure agents, map, etc., all rely on the default Clojure thread pool, which is auto-sized to be N+2 threads, where N=number of cores. That alone would not be so much of a problem except that the Spark jobs run on a YARN cluster, where each Spark executor gets a YARN container, and each YARN container is virtually allocated 1 core from one of the machines in the cluster. Each of the cluster machines is multi-core, so on an 8-core machine, if we allow 5 slots/containers to be allocated, this gives 5 cores to work for scheduled YARN jobs and keeps 3 cores for the machine. Each YARN container is not any sort of VM that enforces an isolated view of the machine, so if all 5 free cores of a single 8-core machine are given to 5 executors of my Spark job, with each executor spinning up a default Clojure thread pool, then the thread pool size will actually be (8+2)=10 threads per executor. Given that each thread is trying to perform blocking I/O, my guess for the job failure is that I saturated I/O quotas on the source file storage system, and that caused executors to stall.
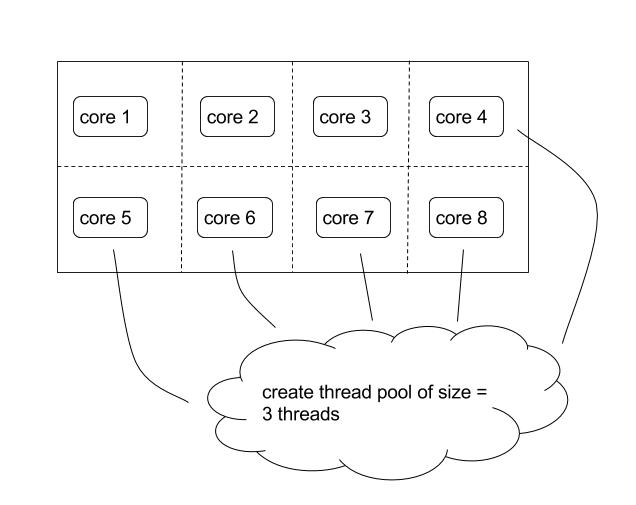
Given my hypothesis, and also prior knowledge that the blocking I/O needs to go on their own dedicated threads, I decided to use Claypoole from the Climate Coroporation, which is a library that allows you to create custom-sized thread pools. It also gives you custom versions of functions like pmap that will handle the custom-sized thread pool management and exceptions for you automatically. Climate Corp also created clj-spark, the progenitor to Flambo, so a big thanks to the work that they’ve done. Claypoole makes it dirt simple to map an operation onto a seq on a custom-sized thread pool — just replace (map f seq) with (tpool/pmap num-threads f seq). It really is only 1 line of code!
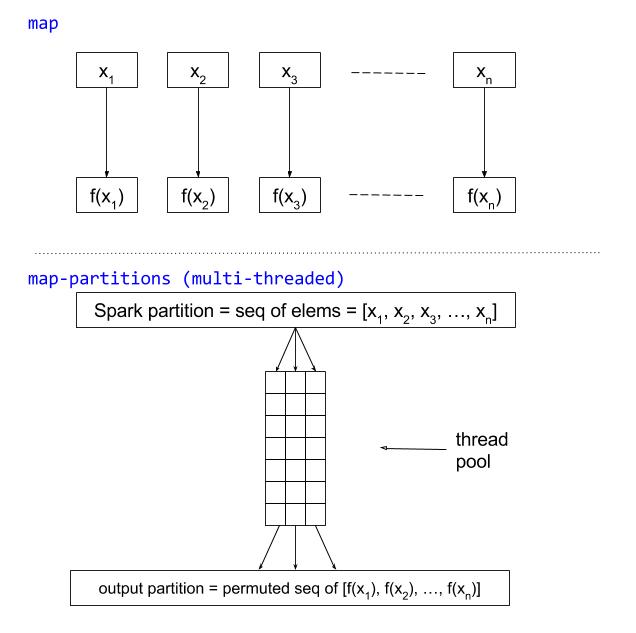
The trick in Spark, in order to create a situation where an executor can run an operation using multiple threads, is to replace a .map operation with a .mapPartitions operation. The .mapPartitions operation is a slightly lower-level operation that accepts all of the values in a Spark RDD partition as a sequence and leaves it up to the user to return the processed (map’ed) values as a sequence. map differs from map-partitions in that map runs each element in a partition serially through the function — map is simpler and easier than map-partitions and for most purposes sufficiently performant. In Scala Spark, the input and output sequences must be Iterators, while in Java Spark (which is what Flambo wraps), the input is an Iterator, and the output must be an Iterable. Clojure allows you to convert Iterators into seqs, since the former are mutable and the latter aren’t. But unsurprisingly, it doesn’t make it easy to create Iterators. And that was the hard part. The following is the helper function that I created that returns a function that can be passed to Flambo’s map-partitions function:
My implementation of an Iterator in Clojure out of a seq may be overly complicated. Suggestions are welcome, but I don’t mind too much, at the same time. The reason is that iterators are inherently mutable, and Clojure seqs create an immutable abstraction that is similar, but by default, is simpler to reason about. Clojure as a language has created a world where simpler concepts are made easier and complex concepts are harder to achieve, and my ugly code preserves that property. 🙂
Checking Your Work
Did all this work actually the OutOfMemoryError that I was experiencing using Spark + core.async (using the default thread pool)? I still don’t yet know because, to be fair, I changed 2 things at the same time. I switched core.async for pmap, and I switched the default thread pool in each Spark executor to a smaller thread pool of my own size. Having recently watched Stu Halloway’s Conj 2015 talk on debugging using the scientific method, I feel a little embarrassed. One way I can go back and isolate variables in my testing is to use my Spark + pmap implementation with thread pools sized the same as the default thread pool (10 threads), and adding logging into my jobs to collect the data to dispel the inherent doubt and hubris of my previous assumptions. So do as I say, and not as I did: watch Stu’s talk, and carry that sense of discipline and rigor about you in all your work so that you can make every statement about your program with confidence. (Edit 1/25/16: I did go back and increase the number of threads in the executor’s thread pool without incurring errors. So my original problem was in just mis-applying the notion of “lightweight threads” in core.async.)
Effective Flambo usage
For any other people interested in writing Spark jobs in Clojure using Flambo, here are some tips to help you navigate the Clojure-specific concerns of writing Spark jobs:
- If the functions you pass to Spark depend on values known only at runtime, then create helper functions that return serializable functions. (The reason is that the serializable fn library will serialize everything in scope into the fn object. The helper function constrains the context of the returned serializable fn to be only what you pass into the helper fn.) Ex:
- Certain Clojure functions can’t be used in the reachable scope/context of a serializable fn definition — ex:
for,letfn. Continuing the example, if you need to transform one map into another, instead of using(into {} (for [[k v] some-map] ...)), usereduce-kvinstead. - Using plain Clojure data structures to represent data in Flambo means data serialization between transformations will become much less a problem for you than it seems to be for Scala Spark users (of course, for any type not automatically handled by Flambo — ex: joda-time
DateTimeorLocalDate, you’ll need to register a serializer with the Kryo registrator.)
Miscellaneous — Flambo and Clojure-Scala interop
One thing that I found out after I went looking for it is that there is a Clojure library called from-scala that makes Scala interop mostly not-bad. Perhaps, in the future, if there are features that come out in Scala Spark that do not make it to Java Spark, then this library can be used to wrap those features in Flambo and Sparkling with much less pain than calling Scala-compiled code from Java.
On further inspection of Flambo, it seems that it easily handles the Spark Java API in a way that is extremely simple and sufficient for most purposes.
In Closing
If the Spark work you’re doing is CPU-bound, then you’re better off sticking with map instead of map-partitions. But if you can parallelize blocking I/O (or maybe even if you have genuinely asynchronous operations), you can hack Spark via map-partitions to achieve your desired effect.
I give Clojure a lot of credit in this whole story of parallel / distributed computing. It enabled me to deftly switch my implementation strategy from core.async to Spark. Considering the types of serialization problems that others have had in writing Spark jobs, using Flambo (the Clojure Spark wrapper) is very likely a big improvement with a much smaller set of Spark concerns to keep track of from one job to the next. And finally, the idea to make Spark jobs multi-threaded was actually implemented relatively straightforward and simple. The simplicity of the language and libraries made the work easier, and I don’t know if I would have dared to think about (stumbled upon?) and try this solution if the barrier to entry weren’t that low. It’s great to search for libraries in Clojure for random ideas like “Clojure-Scala interop” and find that they exist and that they are simple. It took no more time to make a Spark job multi-threaded (1.5 days) as it did to convert my core.async code into a Spark job. So in the future, if a distributed computing API like Dataflow becomes a popular standard, then I have confidence that Clojure could once again “clean up and improve whatever it touches” when Dataflow wrappers are made in Clojure, and converting a Spark job into a job using the Dataflow API would be super-straightforward.
